Construction d'un moteur de recherche sémantique alias un système RAG pour un ChatBot LLM¶
Exploitez la puissance de la récupération-augmentation génération (RAG) dans ChatBot LLM¶
Bienvenue dans le domaine de la technologie LLM, où nous vous aidons à créer des systèmes de recherche avancés avec des capacités d'extraction-augmentation-génération (RAG). Plongez dans le monde de RAG, une approche de pointe qui combine le meilleur des modèles IA basés sur la recherche et générateurs pour offrir des performances exceptionnelles de chatbot.
Qu'est-ce qu'un système RAG dans ChatBot LLM ?¶
Un système RAG dans ChatBot LLM fait référence à l'intégration de la récupération-augmentation-génération dans les applications de chatbot. Ce système exploite une approche à deux volets :
- Modèle basé sur la récupération : Accède rapidement à une base de données d'informations pour trouver du contenu pertinent en fonction des requêtes des utilisateurs.
- Modèle générateur : Améliore les informations récupérées en générant des réponses cohérentes et enrichies contextuellement.
| ChatBot LLM standard | Flux de travail RAG pour ChatBot LLM |
|---|---|
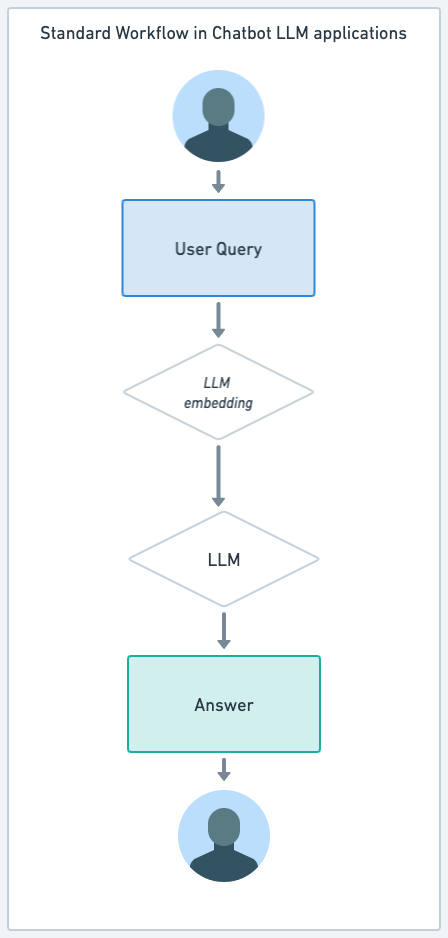 |
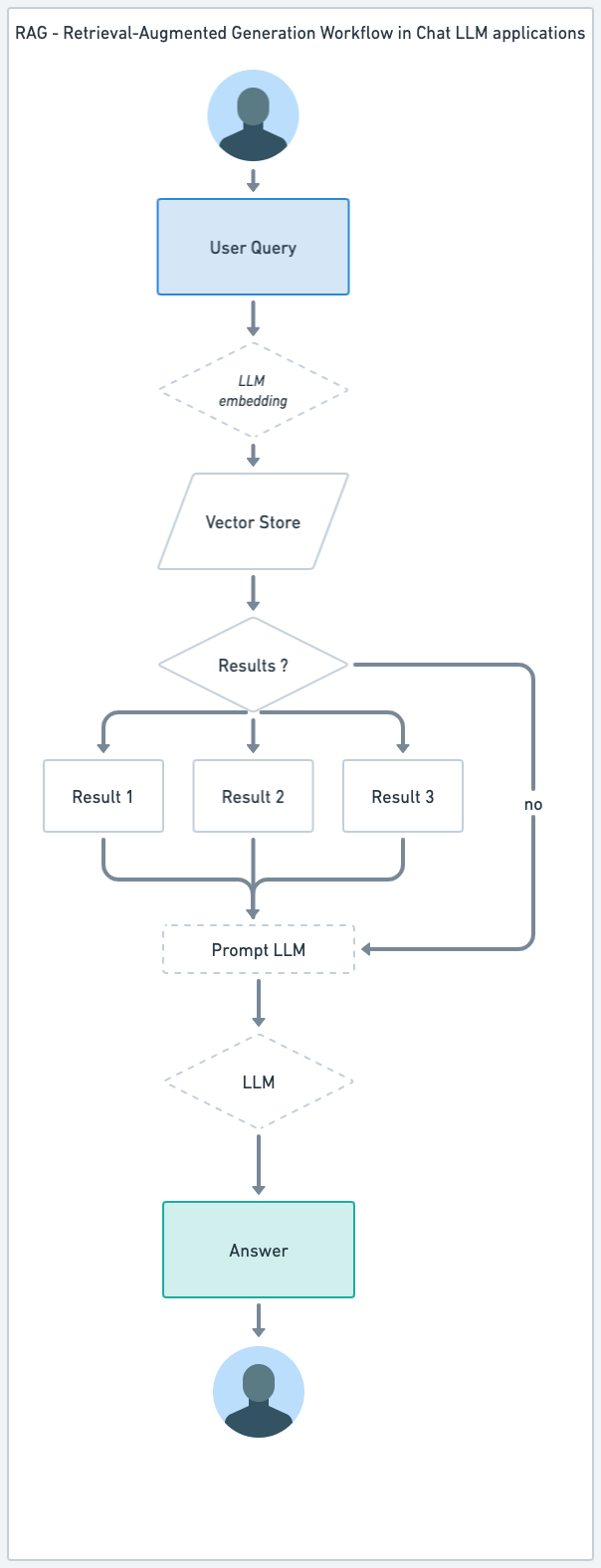 |
Comprendre la différence : Chatbot LLM standard vs système RAG¶
Dans le domaine des chatbots pilotés par l'IA, deux modèles prédominants sont le chatbot LLM standard et le système de récupération-augmentation-génération (RAG). Bien que les deux utilisent des technologies IA avancées, leurs cadres opérationnels et leurs capacités diffèrent considérablement.
Chatbot LLM standard (par ex., ChatGPT, GPT-4)¶
- Interaction directe avec le modèle LLM : Les chatbots LLM standard, tels que ceux basés sur ChatGPT ou GPT-4, interagissent directement avec le modèle de langage large sous-jacent. Ils génèrent des réponses en fonction de la formation et des connaissances encapsulées dans le LLM lui-même.
- Réponses génératives : Ces chatbots excellent dans la création de réponses à partir de zéro, en se basant sur la vaste quantité d'informations et de schémas appris lors du processus de formation du modèle.
- Adaptabilité : Ils sont très adaptables, capables de traiter une large gamme de sujets et de requêtes, mais leurs réponses sont limitées aux connaissances intégrées dans le modèle jusqu'à sa dernière mise à jour de formation.
Système RAG (Récupération-Augmentation-Génération)¶
- Combinaison de modèles de récupération et générateurs : Le système RAG est une approche hybride qui combine un modèle basé sur la récupération avec un LLM générateur comme GPT-4. Il récupère d'abord des informations d'une base de données de vecteurs spécialisée, puis utilise un modèle générateur pour augmenter et contextualiser ces informations.
- Utilisation d'une base de données de vecteurs : Le système RAG utilise un magasin de vecteurs pour une récupération efficace des données pertinentes. Cette base de données contient des représentations vectorielles de haute dimension des informations, permettant une récupération rapide et précise des données en fonction de la similarité des requêtes.
- Pertinence et actualité améliorées : En exploitant le magasin de vecteurs, les systèmes RAG peuvent accéder aux informations les plus récentes, les rendant particulièrement utiles dans les scénarios où des données à jour sont cruciales.
- Réponses dynamiques et contextuelles : La composante générative du système RAG enrichit ensuite les données récupérées, garantissant que les réponses sont non seulement précises mais aussi nuancées et détaillées sur le plan contextuel.
Avantages pour différents rôles :¶
Pour les clients, un système RAG améliore leur expérience en fournissant des informations plus précises, à jour et contextuellement pertinentes. Cela conduit à une plus grande satisfaction et confiance dans les services fournis.
Pour les employés, le système RAG sert d'outil puissant pour accéder aux dernières connaissances et données organisationnelles. Il soutient la prise de décision efficace et la résolution de problèmes, ce qui augmente la productivité et l'efficacité dans leurs rôles.
En résumé, tandis que les chatbots LLM standard offrent une large gamme de capacités génératives, les systèmes RAG élèvent cela en combinant les dernières techniques de récupération de données avec le talent créatif des modèles générateurs. Cette approche hybride rend les systèmes RAG particulièrement avantageux dans les scénarios nécessitant à la fois précision et fluidité conversationnelle.
Comment fonctionne le composant d'un système RAG dans un ChatBot LLM ?¶
1. Modèle basé sur la récupération :¶
Le composant basé sur la recherche d'un système RAG dans un ChatBot LLM fournit la base pour fournir des informations précises et pertinentes. Contrairement au ChatBot LLM de base, qui est directement connecté à un modèle LLM, le RAG vous permet de vous connecter à des modèles de données privées ou à des modèles de données créés spécifiquement pour l'utilisation du chatbot LLM ou du moteur de recherche LLM.
Ce modèle fonctionne comme suit :
- Accès rapide aux données : En utilisant des algorithmes de recherche avancés utilisant des incrustations, le modèle de récupération analyse rapidement des bases de données étendues pour localiser des informations qui correspondent aux demandes des utilisateurs.
- Correspondance de pertinence : Il évalue la pertinence des données récupérées, garantissant que les réponses sont directement liées à la requête ou au besoin spécifique de l'utilisateur.
- Intégration efficace : S'intègre de manière transparente à l'interface conversationnelle du chatbot, assurant une transition fluide entre la saisie de la requête et la récupération des données.
2. Modèle générateur :¶
L'aspect générateur du système RAG améliore les capacités du chatbot en ajoutant une couche de compréhension du contexte et de génération de réponses. Lorsque les bases de données personnalisées retournent leurs réponses, un modèle LLM travaille sur la réponse à afficher à l'utilisateur. Il génère des objets demandés (voir les cas d'utilisation de l'IA) pour répondre à l'utilisateur.
Ce modèle fonctionne comme suit :
- Enrichissement contextuel : Après avoir reçu les données pertinentes du modèle de récupération, le modèle générateur les interprète et les contextualise dans le cadre de la conversation en cours.
- Réponses personnalisées : Il génère des réponses qui sont non seulement précises mais également adaptées au style de conversation, aux préférences et à l'historique de l'utilisateur, offrant une interaction plus personnalisée.
- Interaction dynamique : Le modèle adapte ses réponses pour correspondre au contexte évolutif de la conversation, garantissant que chaque réponse est cohérente et contextuellement appropriée, améliorant le flux global du dialogue.
Ensemble, les modèles basés sur la récupération et générateurs au sein d'un système RAG créent un ChatBot LLM qui est non seulement efficace dans la récupération de données mais aussi capable de créer des réponses riches en contexte et personnalisées. Cette approche à deux volets révolutionne la manière dont les chatbots comprennent et interagissent avec les utilisateurs, établissant une nouvelle norme dans la communication pilotée par l'IA.
Dans les applications avancées de l'IA, la recherche sémantique RAG peut devenir l'un des composants clés, comme d'autres cas d'utilisation de l'IA générative.
Pourquoi implémenter un moteur de recherche sémantique basé sur un système RAG dans votre ChatBot LLM ?¶
- Précision et pertinence améliorées : Combine la récupération précise des informations avec la flexibilité créative des modèles générateurs pour des réponses plus précises et pertinentes.
- Interactions utilisateur enrichies : Fournit des réponses détaill